Search Code
TeamForge Code Search powered by Elasticsearch
TeamForge's Code Search feature uses Elasticsearch as its engine for the indexing and retrieval of documents. Elasticsearch, used in TeamForge, has no customizations other than what is provided via its engine and API. For more information about Elasticsearch, refer to its documentation.
TeamForge Code Search (Elasticsearch): How it works?
Elasticsearch provides the engine for the indexing and retrieval of documents. TeamForge is equipped with its own indexes that extract source files from the SCM repositories and send them to the Elasticsearch engine for indexing. These indexers run as an hourly cron job. When the job starts, it calls an interal TeamForge API that returns the list of repositories to be indexed on the specified SCM integration server. The indexer then processes the repositories, one at a time, starting with the repository that was most recently committed to. For each repository, it determines if a full indexing is needed or just an incremental indexing is sufficient to catch up since the last indexing operation. It then goes down the list of files and processes them for indexing. Only files that need to be indexed are extracted. For example, large binary files are not extracted as they would be indexed anyaway. As the indexers crawl a repository, it would skip any file that is greater than 1 MB. To index a file it has to be UTF8 text.Files are scanned for file encoding and converted to UTF8 if required. Binary files are skipped by the indexers as would be files that cannot be converted to UTF8 format. All files that are skipped are logged along with the reason.
The engine in Elasticsearch is configured to convert the source to lower case and tokenize it. A Camel case filter is used so that common programming elements are broken into individual tokens based on camel case and other common separators used in function names etc. A set of common programming terms (if, then, else, return, exit etc.) are not indexed by default.
How the data is indexed does effect the search results as partial matches are not generally returned. For example, consider a function name in the source code such as: TeamForgeHelper. This would be indexed so that a search for any of these terms would find a match: Team, Forge, Helper, TeamForgeHelper. Nothing else would match, including "TeamForge" or "Tea".
Search results are returned to users with TeamForge RBAC applied to it at a repository level. In other words, a user must have permission to view the entire repository to be able to search it. This works with SVN Path-based permissions (PBP), but only if PBPs are being used to restrict write access. If PBP's are used to deny the user view access to certain paths in the repository, then TeamForge Code Search denies the user the ability to search the repository.
Considerations while upgrading to TeamForge 17.1 (or later)
Consider the following points while upgrading from TeamForge 16.10 (or earlier) to TeamForge 17.1 (or later) versions.
- Code Search is now an integral part of TeamForge, which is installed by default during TeamForge installation
- You can install TeamForge Code Search either on the TeamForge Application Server or on a separate SCM integration Server. It is recommended to install TeamForge Code Search on a separate server if your site's indexing needs are considerable high (large number of repositories, for example).
- TeamForge Code Search works with GIT and SVN repositories.
- Installation of Elasticsearch is determined by adding the "codesearch" identifier to the SERVICES token of either the TeamForge Application Server or the SCM Integration Server (if Code Search runs on a separate server). Refer to the
site-options.confconfiguration section of TeamForge installation/upgrade instructions for more information. - Elasticsearch needs 2GB of JVM heap size by default on a TeamForge site. You must have adequate RAM to accomodate the JVM heap requirements of Elasticsearch in addition to the JVM heap requirements of other components such as Jboss, integrated applications, and so on.
- If required, you can increase the JVM heap size for Elasticsearch. Set the ELASTICSEARCH_JAVA_OPTS token with the Elasticsearch JVM heap size required for your site.
- Elasticsearch stores every document, which for code search is each source file that is indexed, and it has its index itself as well. As a rule of thumb, the index for a repository would be roughly the same size as the working copy for that repository but in practice it will likely be smaller. Consider that all binary files and all files greater than 1 MB are not indexed at all. So, obviously any repository that has large working copy due to these types of files will have a much smaller index. By default, Elasticsearch compresses the original files using LZ4 compression. It also offers a "best_compression" codec that compresses the originals using DEFLATE algorithm. In TeamForge, indexes have been updated to use the maximum compression.
- The Elasticsearch data and logs are stored in /opt/collabnet/teamforge folder. Log rotation, startup and so on are all managed the same way as other TeamForge services.
- As Black Duck Code Sight (BDCS) is not supported:
- remove all BDCS tokens from your
site-options.conffile while upgrading to TeamForge 17.1 or later. TeamForge create runtime fails otherwise. See Site Options Change Log for a list of obsoletesite-options.conftokens. - there is no migraton support for existing BDCS indexes. All the repositories should be indexed afresh post upgrade to TeamForge 17.1 (or later). The list of repositories to index, remains the same though. After upgrading to 17.1 or later, whatever repositories were being indexed by BDCS are indexed by the new Code Search without any user intervention. However, if you had customized indexing for one or more repositories using the BCDS administration UI, such information will have been migrated and would need to be done again, but that can now be done via the TeamForge UI.
- remove all BDCS tokens from your
How to search for Source Code?
Searching repositories for code snippets can be done via the "Jump to ID" search or via the Advanced Search.
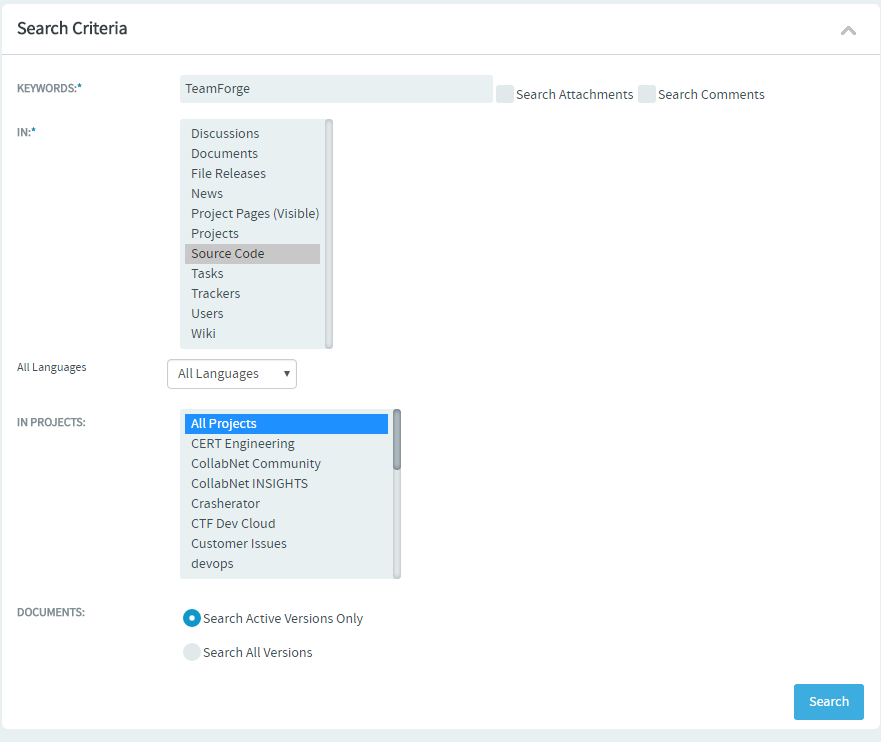
Just select Source Code from the Jump to ID drop-down list, type the search keyword and press enter to search the repositories of the project in context. You can also select Advanced Search from the Jump to ID drop-down list and do an advanced searc for the required code.
-
Click Advanced Search from the Jump to ID drop-down list.
-
Type the search keyword.
-
Select Source Code from the list of components.
-
Set the scope of search: Select
All Languagues(default) or one of the programming languages such as C, C++, C# and so on from the All Languages drop-down list. -
Select either All Projects or a selected few projects (select one or more projects) from the IN PROJECTS list.
-
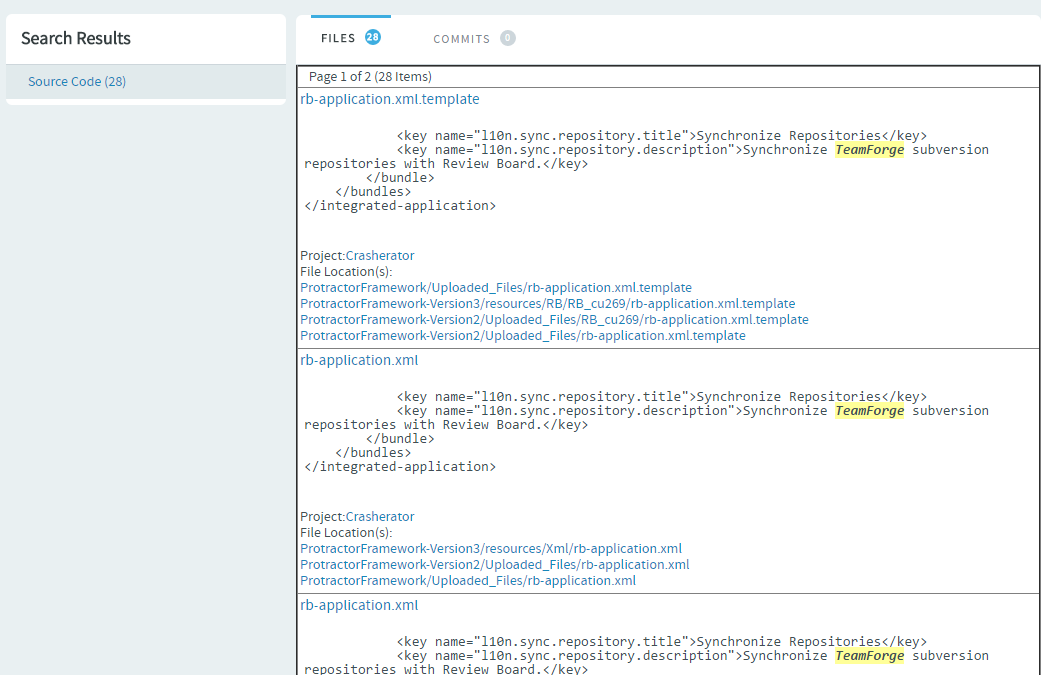
Click Search. The search results are displayed in Files and Commits tabs.
-
In case you want to search for code in a specific repository, select Project Home > Source Code, select a repository you want to search, click Browser Repository, and select the Search tab. You can search all files in a repository or narrow your scope to specific file types such as C, C++, C# and so on.

-
Type your search keyword, select a file extension (optional) and click Search. The search results are displayed in Files and Commits tabs.