TeamForge Tracker Associations Data in Datamart
The following data flow diagram illustrates how the tracker artifact association data makes its way to the datamart.
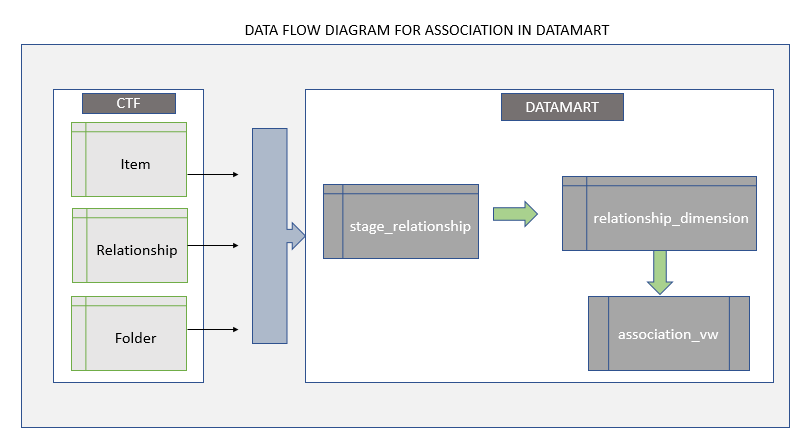
The tracker artifact association data is extracted from the TeamForge's operational database and loaded into the datamart's staging area (stage_relationship). The staged data is then transformed to store association as a dimension (relationship_dimension) in the datamart. A view (association_vw) is then created in de-normalized form for querying purposes.
Increase the ETL memory (via the ETL_JAVA_OPTS site options token) adequately to process the tracker associations data when the ETL job runs for the first time. As a ballpark, 2GB of RAM is required to process 600,000 records of relationship data. You can restore the ETL memory to normal once the first ETL job is over.
Here's the schema that illustrates the design to extract the artifact association data during ETL updates.
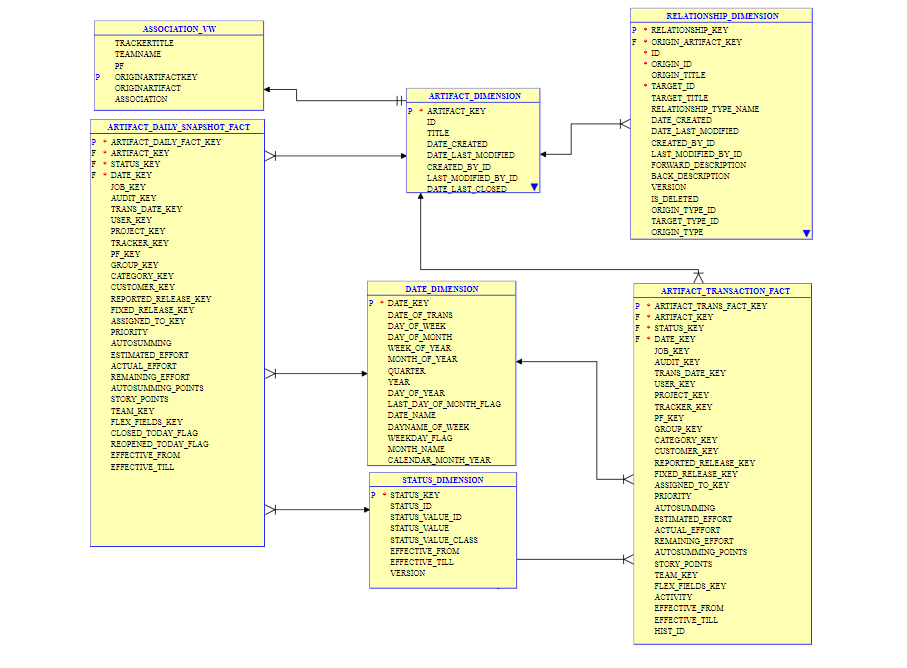
artifact_dimension: The dimension table for storing artifact data. Uses slowly changing dimensions Type-1. Every row in the table corresponds to an artifact.
status_dimension: The dimension table for holding values of the field status. The status_value_class field represents the meta status of an artifact and can be either "Open" or "Close". This table has values for all the artifacts from all the trackers.
date_dimension: Conformed dimension—the date dimension that for storing all the transaction dates.
relationship_dimension: The relationship dimension table for storing relationship attributes. This uses slowly changing dimensions Type-2.
artifact_daily_snapshot_fact: This is an aggregate table that holds the daily snapshot data or end-of-day status. This fact table is to be used for generating reports around artifact close and re-open counts. It is recommended to use the daily snapshot fact table for end-of-day reports as the number of rows will be less compared to the transaction fact table. The daily snapshot table cannot be used to generate activity based reports (except for close and re-open) and for getting intra-day reports.
artifact_transaction_fact: The transaction fact table, granularity=transaction. Every fixed/default field value change to an artifact will make a row insert here, same is true with project/tracker changes caused by artifact move (cut/paste). Flex-field values are not tracked and hence will not make an entry in the artifact_transaction_fact table. The same is true with operations such as adding only comments, attachments, etc. Irrespective of the entires made here, the artifact_dimension.date_last_modified will reflect the time in source system (Tracker) at the time of ETL run. The artifact_transaction_fact table can be used for generating reports around activities such as create, update, delete and move. Intra-day reports also should use this fact table. Total count queries can use the transaction fact, but daily snapshot table will have less number of rows and hence will be faster if end-of-day status is sufficient.
Example Queries
The following SQL query illustrates how to query the schema for both artifact and associations data.
select e.title project,trackertitle as tracker,pf as planningFolder,teamname,c.ID ArtifactId ,date_of_trans as ArtifactTxnDate,
d.status_value_class status, c.id Artifact,story_points,association
from artifact_daily_snapshot_fact a
left join association_vw b on (a.artifact_key =b.originartifactkey)
inner join artifact_dimension c on (a.artifact_key =c.artifact_key)
inner join status_dimension d on (a.status_key =d.status_key)
inner join project_dimension e on (a.project_key =e.project_key)
inner join date_dimension f on (a.trans_date_key =f.date_key)
inner join etl_job g on (a.job_key = g.job_key and g.status = 1)
where current_timestamp between a.effective_from and a.effective_till
order by 1,2,3,4 desc;
The following SQL query just selects the artifact and its association data.
select trackertitle, teamname,pf,originartifact,association from association_vw
All the report generation queries should have a join with the etl_job table with the condition etl_job.status=1 to ignore the data populated by incomplete ETL runs. The is not shown in the example queries above, but is a must when using in production.