Production Environment Installation
This topic is a step-by-step guide on how to set up Deploy in a production-ready environment. It describes how to configure the product, environment, and server resources to get the most out of the product. This topic is structured in three sections:
- Preparation: Describes the prerequisites for the recommended Deploy setup.
- Installation: Covers setup and configuration procedures for each of the components.
- Administration/Operation: Provides an overview of best practices to maintain and administer the system once it is in production.
Proper configuration of I/O subsystems (database, file system, network) is critical for the optimal performance and operation of Deploy. This guide provides best practices and sizing recommendations.
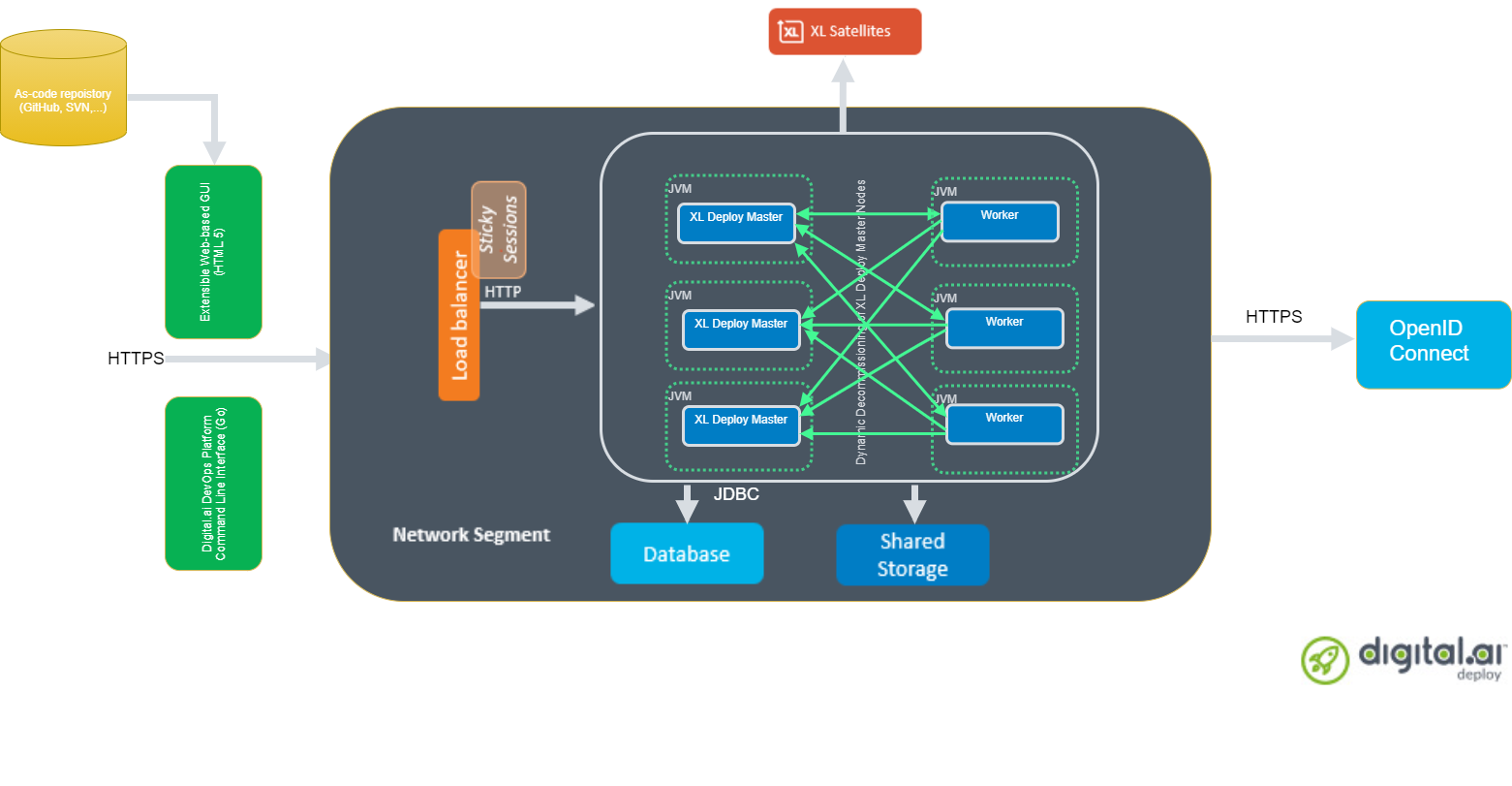
Deploy is active/active capable, and external workers are fully supported. Both are recommended features. The load balancer fronting each of the Deploy servers is required to support sticky sessions based on session cookies when running in active/active mode. Finally, the XL_DEPLOY_SERVER_HOME/exports/ folder should be a shared file system between each of the master nodes.
Hostname resolution between masters and workers is based on DNS lookups. This means localhost and other /etc/hosts-based lookups will fail by default. Although using localhost is considered bad practice, if your installation relies on it you can reinstate the behavior by including a setting pekko.io.dns.resolver = inet-address in deploy-server.yaml.
Production Environment Setup
Preparation
In the first phase of setting up a production environment, you need to determine the correct hardware requirements and obtain the necessary prerequisites. A production-ready Deploy setup is a clustered, multi-node active/active setup with multiple external workers. As such, you will need multiple machines co-located in the same network segment.
Important: It is recommended to have a multi-node setup with odd number of nodes to facilitate high fault tolerance in production environments. It is also recommended not to have a cluster with more than five nodes to prevent database latency issues. You can, however, with some database configuration tuning, have a cluster with more than five nodes. Contact Digital.ai Support for more information about setting up a cluster with more than five nodes.
Alternatives for the recommended setup are to use local workers, or try out a Kubernetes-based setup.
Choosing the correct setup for your requirements
| Type | Possible Configurations | Recommendations | Documentation |
|---|---|---|---|
| Basic installation | Install and run Deploy on a single instance | Recommended if you don't have a high number of concurrent deployments | Basic setup |
| High Scale setup | Setup Deploy to run on one master node and one worker node | Same as basic setup. But provides the flexibility of adding more workers later. | 1. Basic Install 2. Add, start, and use workers |
| Setup Deploy to run on one master and multiple worker nodes | Adds scalability to the basic setup. You can use this setup to run multiple deployment tasks in parallel. Add as many workers as you need to make it scalable. | 1. Basic Install 2. Add, start, and use workers 3. Configure Deploy to use multiple workers | |
| High availability (HA) Setup | Setup Deploy to run on one active master and one or more master nodes in standby | Active—Hot-Standby setup provides scalability with a failover mechanism. You can setup one node to be active and all other nodes to be in standby, waiting to be activated when the active node fails. This setup comes with restrictions and is not recommended for HA. | Set up an Active—Hot-Standby Cluster |
| Setup Deploy to run on multiple master and worker nodes | Active-Active setup adds high availability and high scalability to the basic setup with multiple master and worker nodes. | 1. Set up an Active-Active Cluster 2. Add, start, and use workers 3. Configure Deploy to use multiple workers | |
| Operator-based cluster setup allows you to use the Active-Active setup with the advantages of Kubernetes. | 1. Plan Your Installation or Upgrade 2. Add, start, and use workers |
Other recommendations:
- You can use Satellites with any of these setups for more flexibility.
- In a multi-master HA setup, installing Central Configuration as a microservice makes it easier to manage.
Obtaining Deploy Servers
The Requirements for installing Deploy topic describes the minimum system requirements. Here are the recommended requirements for each Deploy production machine (both masters and workers):
- 3+ Ghz 2 CPU quad-core machine (amounting to 8 cores) or better
- 4 GB RAM or more
- 100 GB hard disk space
Note: All of the Deploy cluster nodes must reside in the same network segment. This is required for the clustering protocol to optimally function. For best performance with minimize network latency, it is also recommended that your database server be located in the same network segment.
Obtaining the Deploy Distribution
Download the Deploy ZIP package from the Deploy/Release Software Distribution site (requires customer log-in).
For information about the supported versions of Deploy, see Supported Digital.ai product versions.
Choosing a Database Server
A production setup requires an external clustered database to store the Deploy data. The supported external databases are described in Configure the Deploy SQL repository.
For more information about hardware requirements, see the database server provider documentation. Important: Derby database is not recommended for production use.
Artifacts Storage Location
You can configure Deploy to store and retrieve artifacts in three different storage repository formats:
- Repository Manager: Artifacts are managed by tools such as Nexus and Artifactory
- Database: The artifacts are stored in and retrieved from a relational database management system (RDBMS)
- File System: The artifacts are stored on and retrieved from the file system
Digital.ai recommendations are, in order of preference:
- A repository management system, with artifacts referenced using the
fileUriproperty on the artifacts. - A clustered database, if the RDBMS supports the size of the artifacts.
- On a shared file system.
Deploy can only use one local artifact repository at any time. The configuration option xl.repository.artifacts.type can be set to either file or db to select the storage repository.
Choosing a Load Balancer
The recommended Deploy production setup is an active/active one, but each user session resides on a single node. As a result, you need to front the installation with a load balancer that supports sticky sessions based on session cookies.
This guide uses HAProxy as an example. You can use any HTTP(s) load balancer that supports the following features:
- SSL offloading
- Checking a custom HTTP endpoint for node availability
- Sticky sessions based on session cookies
Here are examples of load balancers that support this feature set:
Choosing an Authentication Provider
Deploy supports a number of single-sign on (SSO) authentication providers, including Secure LDAP (LDAPS) and OIDC providers. Many cloud providers support authentication through OIDC:
If you do not want to use a cloud provider, or if your SSO solution is not compatible with OIDC, you can integrate your SSO with Keycloak, which is an OIDC bridge.
For more information, see Configure OpenID Connect (OIDC) Authentication for Deploy or Connect Deploy to your LDAP or Active Directory
Choosing a Monitoring and Alerting Solution
For a production installation, make sure you set up a monitoring system to monitor the system and product performance for the components comprising your installation. Deploy exposes internal and system metrics over Java Management Extensions (JMX). Any monitoring system that can read JMX data can be used to monitor the installation.
Common monitoring and alerting tools include:
Choosing a Forensic Data Gathering Toolchain
In addition to monitoring, ensure that system-related data gathering is active and available. You can analyze the gathered forensic data at a later point in time and perform root cause analysis for outages. You can also use forensic data to determine usage and peak load patterns.
For this kind of monitoring, you can use a time series database. Common tools include:
You can graph and analyze the gathered data using a tool such as Grafana.
It is also recommended that you set up log file monitoring. The industry-standard toolchain for log file monitoring is the ELK stack, now referred to as Elastic Stack. The stack consists of:
These tools allow log files to be read and indexed while they are being written, so you can monitor for errant behavior during operation and perform analysis after outages.
Database Server Configuration
The basic database setup procedure, including schemas and privileges, is described in Configure the Deploy SQL repository. For various databases, additional configuration options are required to use them with Deploy or for a better performance.
MySQL or MariaDB
Important:
- MariaDB is not an officially supported database for Deploy, but you can use it as a drop in replacement for MySQL.
- The recommended settings mentioned in this section may vary based on your usage patterns. Contact Digital.ai support for further assistance. The default installation of MySQL is not tuned to run on a dedicated high-end machine. It is recommended that you change the following MySQL settings to improve its performance. These settings can be set in the MySQL options file. See the MySQL documentation to locate this file on your operating system.
| Setting | Value |
|---|---|
innodb_buffer_pool_size | Set this to maximum 70-75% of the available RAM of the database server. This setting controls the size of the database structure that can be kept in memory. Larger size provides better performance for the application due to caching at the database level. |
innodb_log_file_size | Set this to 256M. This sets the size of redo logs that MySQL keeps. If you set this to a large value, MySQL can process peak loads by keeping the transactions in the redo log. |
innodb_thread_concurrency | Set this to 2 * CPU cores of the database server. For example: for a 2 CPU quad-core machine, the optimal setting is 2 CPU * 4 Cores * 2 = 16. |
max_allowed_packet | Set this to 64M. This represents the maximum size of the packet transmitted from the server to the client. As the Deploy database for some columns contains BLOBs, this setting is better than the default of 1M. |
open_files_limit | We recommend setting this value to 10000 for large installations. This setting controls the number of file descriptors the MySQL database can keep open. This setting cannot be set to a higher value than the output of ulimit -n on a Linux/Unix system. If this limit is lower than the recommended value, see the documentation for your operating system. |
innodb_flush_log_at_trx_commit | Advanced: The default setting of this option is 1. Every transaction is always flushed to disk on commit, ensuring full ACID compliance. Setting this to either 0 (only flush the transaction buffer once per second to the transaction log), or 2 (directly write the transaction to the transaction log, flush the log once per second to disk), can produce transaction loss of up to a second worth of data. Note: When using a battery-backed disk cache, this setting can be set to 2 to prevent direct flushes to disk. The battery-backed disk cache ensures that the cache is flushed to disk before the power fails. |
PostgreSQL
There are a number of settings in a default installation of PostgreSQL that can be tuned to better perform on higher end systems. These configuration options can be set in the PostgreSQL configuration file.
Note: For more information on configuring Digital.ai Deploy with Postgres Use Deploy with Postgres
See the PostgreSQL documentation to locate this file on your operating system.
| Setting | Value |
|---|---|
shared_buffers | Set to 30% of the available RAM of the database server. This setting controls the size of the memory allocated to PostgreSQL for caching data. |
effective_cache_size | Set to 50% of the available RAM of the database server. This setting provides an estimate of the memory size available for disk caching. The PostgreSQL query planner uses this setting to figure out if the query plan results can fit in the memory or not. |
checkpoint_segments | Set to 64. This setting controls how often the Write Ahead Log (WAL) is check-pointed. The WAL is written in 16MB segments. If you set this to 64, the WAL is check-pointed once every 64 * 16MB = 1024MB or once per 5 minutes, whichever is reached first. |
default_statistics_target | Set to 250. This setting controls the amount of information stored in the statistics tables for optimizing query execution. |
work_mem | Set to 0.2% of the available RAM of the database server. This setting controls the memory size available per connection for performing memory sorts and joins of query results. In a 100 connection scenario, this will be 20% of the available RAM in total. |
maintenance_work_mem | Set to 2% of the available RAM. This setting controls the amount of memory available to PostgreSQL for maintenance operations such as VACUUM and ANALYZE. |
synchronous_commit | Advanced: The default setting of this option is on. This guarantees full ACID compliance and no data loss on power failure. If you have a battery-backed disk cache, you can switch this setting to off to produce an increase in transactions per second. |
Security Settings
It is important to harden the Deploy environment from abuse. There are many industry-standard practices to ensure that an application runs in a sandboxed environment. You should minimally take the following actions:
- Run Deploy in a VM or a container. There are officially supported docker images for Deploy.
- Run Deploy on a read-only file system. Deploy needs to write to several directories during operation, specifically its
conf/,export/,log/,repository/, andwork/subdirectories. The rest of the file system can be made read-only. (Theexport/directory needs to be shared between Deploy master instances) - Enable SSL on JMX on Deploy server and satellites. See Using JMX counters for Deploy Satellite and
centralConfiguration/deploy-jmx.yaml. - Configure secure communications between Deploy and satellites.
- Add your production-ready database as described above.
- Do not enable SSL since the load balancer will offload SSL as described in Finalize the node configuration and start the server.
Operating System
Deploy supports running on any commercially supported Microsoft Windows Server version (under Mainstream Support), or any Linux/Unix operating systems. Ensure that you maintain these systems with the latest security updates.
Java Version
Important: Deploy requires Java SE 8 or Java SE 11. Running Deploy on non-LTS Java versions is not supported. See the Java SE support roadmap for details and dates.
Deploy can run on the Oracle JDK or JRE, as well as OpenJDK. Always run the latest patch level of the JDK or JRE, unless otherwise instructed. For more information on Java requirements see Requirements for installing Deploy.
Installation and Execution
The Deploy installation procedure for both master and worker nodes is the same. To install Deploy on the machines with the minimum required permissions:
Linux/Unix Operating Systems
- Create a dedicated unprivileged non-root user called
xl-deploy. This ensures that you can lock down the operating system and prevent accidental privilege escalations. - Create a directory under
/optcalledxebialabs, where thexl-deployuser hasreadaccess. - Extract the downloaded version of Deploy in the
/opt/xebialabsdirectory. - Change the ownership of the installed product to
xl-deployand grant the userreadaccess to the installation directory. - Grant the
xl-deployuserwriteaccess underneath the/opt/xebialabs/xl-deploy-<version>-server/folder to theconf/andlog/subdirectories. For password encryption purposes, the user should have write access tocentralConfigurationdirectory. The user should also be able to create new subdirectories, or have write access to theexport/,repository/,work/, andplugins/subdirectories. Finally, ensure that all files in thelog/subfolder have write permissions. The server will start without them, but no logging will be available. Theexport/subdirectory should be a shared filesystem across all masters and workers. - Copy your license file to the
/opt/xebialabs/xl-deploy-<version>-server/confdirectory. You can download your license file from the Deploy/Release Software Distribution site (requires customer log-in).
Microsoft Windows Operating Systems
- Create a dedicated unprivileged non-Administrator account called
xl-deploy. This ensures that you can lock down the operating system and prevent accidental privilege escalations. - Create a directory
C:\xebialabs, where thexl-deployuser has defaultRead,List folder contentsandRead & Executeaccess. - Extract the downloaded version of Deploy into the
C:\xebialabs\xl-deployit-<version>-serverdirectory. - Grant the
xl-deployuserRead,Read & execute,List folder contents, andWritepermissions to this installation directory so Deploy can add and modify necessary files and create subdirectories. Alternatively, grantWritepermission to theconf\,log\, andplugins\folders, and to the newly to be createdexport,repository, andworksubdirectories. (In case of workers, the work directory will be called differently.) - Copy your license file to the
C:\xebialabs\xl-deploy-<version>-server\confdirectory. You can download your license file from the Deploy/Release Software Distribution site (requires customer log-in).
Configure the SQL Repository
For a clustered production setup, Deploy requires an external database, as described in Configure the Deploy SQL repository.
Configure Deploy Master-Worker Connectivity
The suggested production setup uses external workers to execute deployments and control tasks. On each node, edit centralConfiguration/deploy-task.yaml to include a setting deploy.task.in-process-worker=false. On each of the nodes running Deploy as a worker instance, the -master <address>:<port> flags' addresses will be resolved against DNS, so you need to make sure that your DNS server resolves each as an A record or an SRV record listing each of the Deploy master instances. For more information, see deploy-task (deploy-task.yaml).
Configure the Task Queue
Since the suggested production setup uses external workers and these in turn require an external task queue to be configured, refer to Configure task queueing to set up and configure an external task queue for use with Deploy.
Configure User Authentication
Set up a secure process for authenticating users. For production setups, you can use an OIDC provider, use Keycloak as an OIDC bridge, or use an LDAP directory system over the LDAPS protocol.
For more information, see:
- Choosing an authentication provider
- Configure OpenID Connect (OIDC) Authentication for Deploy
- Connect Deploy to your LDAP or Active Directory
Configure Deploy Java Virtual Machine (JVM) Options
To optimize Deploy performance, you can adjust JVM options to modify the runtime configuration of Deploy. To increase performance, add or change the following settings in the conf/xld-wrapper.conf.common file.
| Setting | Value |
|---|---|
-server | Instructs the JVM to run in the server profile. |
-Xms8192m | Instructs the JVM to reserve a minimum of 8 GB of heap space. If you have less than 10GB memory dedicated to your (virtual or physical) machine, lower this number accordingly. (Note that the operating system itself also needs memory) |
-Xmx8192m | Max heap size. Set this to the same number as the previous setting to get optimal performance from the Parallel garbage collector (enabled below) |
-XX:MaxMetaspaceSize=1024m | Instructs the JVM to assign 1 GB of memory to the metaphase region (off-heap memory region for loading classes and native libraries). |
-Xss1024k | Instructs the JVM to limit the stack size to 1 MB. |
-XX:+UseParallelGC | Instructs the JVM to use the Parallel garbage collector, which is the default garbage collector used by Deploy. |
-Dsun.net.inetaddr.ttl=60 | Limits DNS caching to 60s. |
-XX:+HeapDumpOnOutOfMemoryError | Instructs the JVM to dump the heap to a file in case of an OutOfMemoryError. This is useful for debugging purposes if the Deploy process crashes. |
-XX:HeapDumpPath=log/ | Instructs the JVM to store generated heap dumps in the log/ directory of the Deploy server. |
Large artifacts and high parallelism increase heap pressure. Even when your Deploy version supports artifacts larger than 2 GB, running many deployments in parallel can still lead to OutOfMemoryError if the heap is undersized.
If you deploy large file.Folder artifacts, review copy strategy guidance and large-artifact behavior in Copy Strategies.
Configure the Task Execution Engine
Deployment tasks are executed by the Deploy workers' task execution engines. Based on your deployment task, one of the Deploy master instances generates a deployment plan that contains steps that one of the Deploy workers will carry out to deploy the application. You can tune the Deploy worker's task execution engine with the settings described in Configure the task execution engine. Note that a worker is only eligible for executing a deployment task when its configuration matches the master's that generated the deployment plan.
Finalize the Node Configuration and Start the Server
After the node(s) are configured for production use, you can finalize the configuration.
Run the /opt/xebialabs/xl-deploy-<version>-server/bin/run.sh or C:\xebialabs\xl-deploy-<version>-server\bin\run.cmd script on a single node to start the Deploy server.
Because this is the initial installation, Deploy prompts a series of questions. See the table below for the questions, recommended responses, and considerations.
| Question | Answer | Explanation |
|---|---|---|
| Do you want to use the simple setup | no | Some properties need to be changed for production scenarios. |
| Please enter the admin password | ... | Choose a strong and secure admin password. |
| Do you want to generate a new password encryption key | yes | You should generate a random unique password encryption key for the production environment. |
| Please enter the password you wish to use for the password encryption key | ... | If you want to start Deploy as a service on system boot, do not add a password to the password encryption key. Adding a password to the encryption key prevents automated start. If your enterprise security compliance demands it, you can add a password in this step. |
| Would you like to enable SSL | no | SSL offloading is done on the load balancer. In this scenario, it is not required to enable SSL on the Deploy servers. |
| What HTTP bind address would you like the server to listen to | 0.0.0.0 | Add this address to listen on all interfaces. If you only want to listen on a single IP address/interface, specify that one. |
| What HTTP port number would you like the server to listen on | 4516 | This is the default port; you can enter a different port number. |
| Enter the web context root where Deploy will run | / | By default, Deploy runs on the / context root (in the root of the server). |
| Enter the public URL to access Deploy | https://LOADBALANCER_HOSTNAME | For Deploy to correctly rewrite all the URLs, it must know how it can be reached. Enter the IP address or hostname configured on the load balancer, instead of the IP address (and port) of the Deploy server itself. The protocol is https. |
| Enter the minimum number of threads for the HTTP server | 30 | Unless otherwise instructed, the default value can be used. |
| Enter the maximum number of threads for the HTTP server | 150 | Start with the default value. If the monitoring points to thread pool saturation, this number can be increased. |
| Do you agree with these settings | yes | Type yes after reviewing all settings. |
After you answer yes to the final question, the Deploy server will boot up. During the initialization sequence, it will initialize the database schemas and display the following message:
You can now point your browser to https://<IP_OF_LOADBALANCER>/
Stop the Deploy server. Edit the conf/deployit.conf file and change these configuration options to a hardened setting:
| Option | Value | Explanation |
|---|---|---|
hide.internals | true | Hides exception messages from end users and only shows a key. The Deploy administrator can use this key find the exception. |
client.session.timeout.minutes | 20 | Defines the session idle timeout. Set this to the number of minutes that is defined by your enterprise security compliance officer. |
Copy the conf/repository-keystore.jceks and conf/deployit.conf to the other nodes so that they run on the same settings.
All nodes are now fully configured and can be booted up.
Boot Sequence
Start the nodes:
- Start the master nodes.
- Wait until each of the nodes is reachable at
http://<node_ip_address>:4516/. - Check that each node reports success on a GET request to
http://<node_ip_address>:4516/ha/health - Start each of the worker nodes.
- Check that each worker node connects successfully to each of the master nodes, e.g. by using the CLI command
workers.list()
Running as a Service
Once you are satisfied that the Deploy master instances run without issue, you can install Deploy as a service by executing the bin/install-service.sh or bin\install-service.cmd script.
Configure the Additional Tools
Set up the Load Balancer
This example shows a minimal HAProxy 2.0 load balancer configuration. The sections below show how to set up the routing and health checks for the load balancer.
defaults
mode http # <0>
frontend xl-http # <1>
bind 0.0.0.0:80
http-request redirect scheme https if !{ ssl_fc } # <2>
frontend xl-https # <3>
bind 0.0.0.0:443 ssl crt /path/to/certificate.pem # <4>
default_backend xld-backend # <5>
backend xld-backend # <6>
option httpchk GET /deployit/ha/health # <7>
balance roundrobin # <8>
cookie SESSION_XLD prefix # <9>
server xld-1 xld-server-1.example.com:4516 check cookie abc # <10>
server xld-2 xld-server-2.example.com:4516 check cookie def
server xld-3 xld-server-3.example.com:4516 check cookie ghi
<0>Enable HTTP traffic analysis so we may e.g. redirect traffic (<2>) and manipulate cookies (<9>,<10>)<1>Thexl-httpfront end handles all HTTP requests on port 80<2>Redirect all requests to HTTPS if the front connection was not made using an SSL transport layer.<3>Thexl-httpsfront end will handle all incoming SSL requests on port 443.<4>Ensure you have a properly signed certificate to ensure a hardened configuration.<5>Every incoming request on HTTPS will be routed to thexld-backendback end.<6>Thexld-backendwill handle the actual load balancing for the Deploy nodes.<7>Every Deploy node is checked on the/deployit/ha/healthendpoint to verify whether it is up. If this endpoint returns a non-success status code, the node is taken out of the load balancer until it is back up.<8>New user sessions are distributed round-robin<9>Sticky sessions are supported by putting a prefix on theSESSION_XLDcookie<10>Enable health check and use theabcprefix on theSESSION_XLDcookie to arrange sticky sessions bound to master nodexld-1, prefixdefforxld-2, etc.
Administration and Operation
This section describes how to maintain the running system and what to do if monitoring shows any issues in the system.
Back up Deploy
To prevent inadvertent loss of data, ensure you regularly back up your production database as described in Back up Deploy.
Set up Monitoring
Set up the Desired Metrics
Ensure that you monitor the following statistics for the systems that comprise your Deploy environment including the load balancer, your Deploy nodes, and database servers:
- Network I/O
- Disk I/O
- RAM usage
- CPU usage
Add Monitoring to Deploy
You can remotely monitor JMX, add a Java agent such as the Dynatrace agent, or use a tool such as collectd to push the monitoring statistics to a central collectd server.
In general, it is not recommended that you add Java agents to the Java process. Testing has shown that the Java agents can adversely influence the performance characteristics of the Deploy system. You should also make sure to not expose insecure or unauthenticated JMX over the network, as it can be used to execute remote procedure calls on the JVM.
The optimal solution is to set up collectd to aggregate the statistics on the Deploy server and push them to a central collecting server that can graph them. To do this, you must install the following tools on the Deploy server:
After these tools are installed, you can use this collect.conf sample, which is preconfigured to monitor relevant Deploy application and system statistics:
LoadPlugin network
LoadPlugin java
LoadPlugin disk
LoadPlugin df
LoadPlugin cpu
LoadPlugin interface
<Plugin "network">
Server "<IP_ADDRESS_HERE>"
</Plugin>
<Plugin "interface">
Interface "<NETWORK_INTERFACE_HERE>"
IgnoreSelected false
</Plugin>
<Plugin "disk">
Disk "/^[vhs]d[a-f]$/"
IgnoreSelected false
</Plugin>
<Plugin cpu>
ReportByCpu true
ReportByState true
ValuesPercentage true
</Plugin>
<Plugin df>
FSType sysfs
FSType proc
FSType devtmpfs
FSType devpts
FSType tmpfs
FSType fusectl
FSType cgroup
FSType overlay
FSType debugfs
FSType pstore
FSType securityfs
FSType hugetlbfs
FSType squashfs
FSType mqueue
IgnoreSelected true
ReportByDevice false
ReportReserved true
ValuesAbsolute true
ValuesPercentage true
ReportInodes true
</Plugin>
<Plugin "java">
JVMARG "-Djava.class.path=/usr/share/collectd/java/collectd-api.jar:/usr/share/collectd/java/collectd-fast-jmx.jar"
LoadPlugin "com.e_gineering.collectd.FastJMX"
<Plugin "FastJMX">
MaxThreads 256
CollectInternal true
<MBean "classes">
ObjectName "java.lang:type=ClassLoading"
<Value "LoadedClassCount">
Type "gauge"
InstancePrefix "loaded_classes"
PluginName "JVM"
</Value>
</MBean>
# Time spent by the JVM compiling or optimizing.
<MBean "compilation">
ObjectName "java.lang:type=Compilation"
<Value "TotalCompilationTime">
Type "total_time_in_ms"
InstancePrefix "compilation_time"
PluginName "JVM"
</Value>
</MBean>
# Garbage collector information
<MBean "garbage_collector">
ObjectName "java.lang:type=GarbageCollector,*"
InstancePrefix "gc-"
InstanceFrom "name"
<Value "CollectionTime">
Type "total_time_in_ms"
InstancePrefix "collection_time"
PluginName "JVM"
</Value>
<Value "CollectionCount">
Type "counter"
InstancePrefix "collection_count"
PluginName "JVM"
</Value>
</MBean>
<MBean "memory_pool">
ObjectName "java.lang:type=MemoryPool,*"
InstancePrefix "memory_pool-"
InstanceFrom "name"
<Value>
Type "memory"
Table true
Attribute "Usage"
</Value>
</MBean>
<MBean "memory-heap">
ObjectName "java.lang:type=Memory"
InstancePrefix "memory-heap"
<Value>
Type "memory"
Table true
Attribute "HeapMemoryUsage"
</Value>
</MBean>
<MBean "memory-nonheap">
ObjectName "java.lang:type=Memory"
InstancePrefix "memory-nonheap"
<Value>
Type "memory"
Table true
Attribute "NonHeapMemoryUsage"
</Value>
</MBean>
<MBean "thread">
ObjectName "java.lang:type=Threading"
InstancePrefix "threading"
<Value>
Type "gauge"
Table false
Attribute "ThreadCount"
InstancePrefix "count"
</Value>
</MBean>
<MBean "thread-daemon">
ObjectName "java.lang:type=Threading"
InstancePrefix "threading"
<Value>
Type "gauge"
Table false
Attribute "DaemonThreadCount"
InstancePrefix "count-daemon"
</Value>
</MBean>
<MBean "jvm_runtime">
ObjectName "java.lang:type=Runtime"
<Value>
Type "counter"
InstancePrefix "runtime-uptime"
Table false
Attribute "Uptime"
</Value>
</MBean>
<MBean "jvm_system">
ObjectName "java.lang:type=OperatingSystem"
<Value>
Type "gauge"
InstancePrefix "os-open_fd_count"
Table false
Attribute "OpenFileDescriptorCount"
</Value>
<Value>
Type "counter"
InstancePrefix "os-process_cpu_time"
Table false
Attribute "ProcessCpuTime"
</Value>
</MBean>
<MBean "jetty_qtp">
ObjectName "org.eclipse.jetty.util.thread:type=queuedthreadpool,id=0"
InstancePrefix "jetty_qtp"
<Value>
Type "gauge"
InstancePrefix "busy_threads"
Table false
Attribute "busyThreads"
</Value>
<Value>
Type "gauge"
InstancePrefix "idle_threads"
Table false
Attribute "idleThreads"
</Value>
<Value>
Type "gauge"
InstancePrefix "max_threads"
Table false
Attribute "maxThreads"
</Value>
<Value>
Type "gauge"
InstancePrefix "queue_size"
Table false
Attribute "queueSize"
</Value>
</MBean>
# xlrelease metrics
<MBean "xlr-api-int">
ObjectName "com.xebialabs.xlrelease.metrics.api.internal:*"
InstancePrefix "xlr-api-int"
<Value "Count">
Type "counter"
InstanceFrom "name"
PluginName "XLR"
</Value>
<Value "Sum">
Type "derive"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "xlr-api-v1">
ObjectName "com.xebialabs.xlrelease.metrics.api.v1:*"
InstancePrefix "xlr-api-v1"
<Value "Count">
Type "counter"
InstanceFrom "name"
PluginName "XLR"
</Value>
<Value "Sum">
Type "derive"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "xlr-repo">
ObjectName "com.xebialabs.xlrelease.metrics.repository:*"
InstancePrefix "xlr-repo"
<Value "Count">
Type "counter"
InstanceFrom "name"
PluginName "XLR"
</Value>
<Value "Sum">
Type "derive"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "xlr-repo-jcr">
ObjectName "com.xebialabs.xlrelease.metrics.repository.jcr:*"
InstancePrefix "xlr-repo-jcr"
<Value "Count">
Type "counter"
InstanceFrom "name"
PluginName "XLR"
</Value>
<Value "Sum">
Type "derive"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "xlr-exec">
ObjectName "com.xebialabs.xlrelease.metrics.executors:*"
InstancePrefix "xlr-exec"
<Value "Count">
Type "counter"
InstanceFrom "name"
PluginName "XLR"
</Value>
<Value "Sum">
Type "derive"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "xlr-pool">
ObjectName "com.xebialabs.xlrelease.metrics.pool.repository:*"
InstancePrefix "xlr-pool"
<Value "Value">
Type "gauge"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "xlr-handler">
ObjectName "com.xebialabs.xlrelease.metrics.handler:*"
InstancePrefix "xlr-handler"
<Value "Count">
Type "counter"
InstanceFrom "name"
PluginName "XLR"
</Value>
<Value "95thPercentile">
Type "gauge"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<MBean "kamon">
ObjectName "kamon:type=pekko-dispatcher,name=*"
InstancePrefix "kamon"
<Value "Avg">
Type "gauge"
InstanceFrom "name"
PluginName "XLR"
</Value>
</MBean>
<Connection>
ServiceURL "service:jmx:rmi:///jndi/rmi://localhost:1099/jmxrmi"
User "{{ jmx_username }}"
Password "{{ jmx_password }}"
IncludePortInHostname true
Collect "classes"
Collect "thread"
Collect "thread-daemon"
Collect "compilation"
Collect "garbage_collector"
Collect "memory_pool"
Collect "memory-heap"
Collect "memory-nonheap"
Collect "jvm_system"
Collect "jvm_runtime"
Collect "jetty_qtp"
Collect "xlr-api-int"
Collect "xlr-api-v1"
Collect "xlr-repo"
Collect "xlr-repo-jcr"
Collect "xlr-exec"
Collect "xlr-pool"
Collect "xlr-handler"
Collect "kamon"
TTL {{ jmx_ttl }}
</Connection>
</Plugin>
</Plugin>
To use this sample, save it as collectd.conf, and add two configuration values to the configuration:
IP_ADDRESS_HERE: Enter the IP address of the centralcollectdserverNETWORK_INTERFACE_HERE: Enter the network interface over which Deploy communicates
Connectivity to Middleware
This section reviews how Deploy will traverse your network to communicate with middleware application servers to perform deployment operations. Since Deploy is agentless, communication is done using standard SSH or WinRM protocols.
Standard Deploy Connectivity
In this example, Deploy, using the Overthere plugin, connects to the target server using either SSH or WinRM.
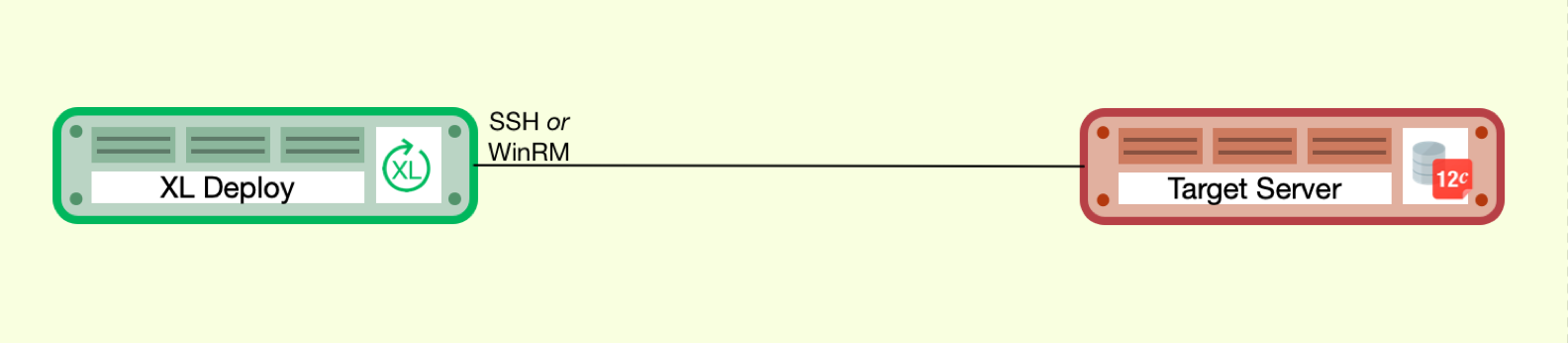
For more information, review the following:
Standard Deploy Connectivity Using Jumpstation
- Deploy, using the Overthere plugin, connects to the jumpstation target server using SSH. Nothing is installed on the jumpstation server.
- Connection is made from jumpstation, using SSH or WinRM, to the target server.

For more information, see Jumpstation details and Connect Deploy through an SSH jumpstation or HTTP proxy
Standard Deploy Connectivity Using Satellite
How it works:
- Deploy communicates to Deploy Satellite application using TCP.
- Deployment workload is moved from Deploy JVM to Deploy Satellite.
- Deploy Satellite, using the Overthere plugin, connects to the Target server using SSH or WinRM.

For more information, see getting started with the satellite module.
Communication Protocols and Capabilities
| Deploy Outbound Connection Type | Outbound Connections to Target Servers | Deployment Tasks | Control Tasks | UI Extensions | |
|---|---|---|---|---|---|
| Deploy Server | - | SSH, WinRM | Y | Y | Y |
| Deploy Satellite | TCP | SSH, WinRM | Y | Y | N |
| Jumpstation | SSH | SSH, WinRM | N/A | N/A | N/A |
Configure websockets
To optimize Deploy performance, you can adjust interactive communication session between the Deploy and the server by changing the default following settings in the centralConfiguration/xld-websockets.yaml file.
deploy.websockets:
message-broker:
input-buffer-size: 32768
threadpool:
core-pool-size: 10
daemon: false
keep-alive-seconds: 180
max-pool-size: 24
queue-capacity: 500
Jumpstation Details
Jumpstation:
- Uses standard SSH encryption
- Can use PKI or User credentials
- Uses a TLS-encrypted satellite connection
- Will create a tunnel to allow direct communication to a target host
- Port (configurable): 22 default
- Port only open during communications. Pipe closed after task executed
- Is bi-directional during activity
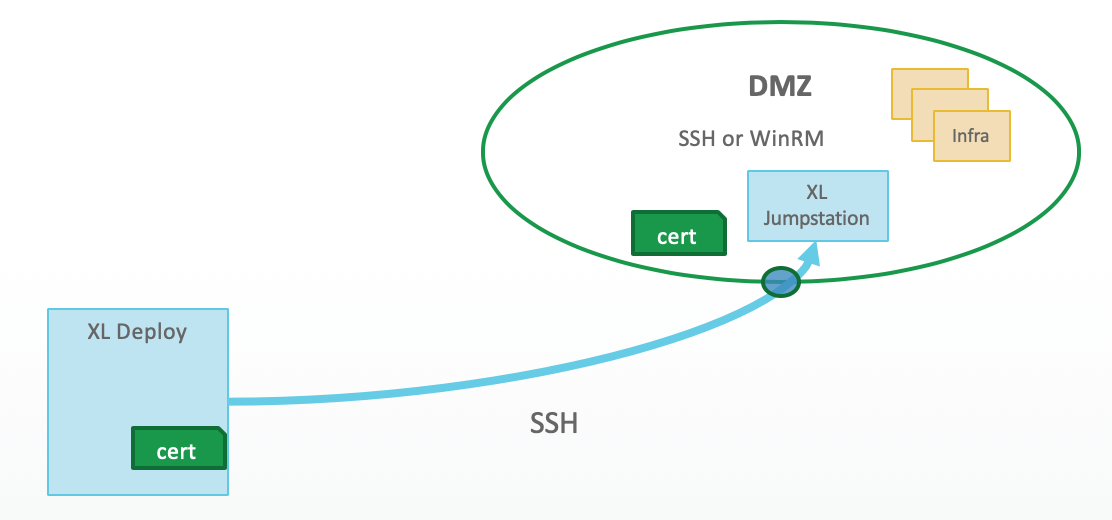
With this set up, you then need to:
- Establish connectivity method (credentials, or signed certificate).
- Define a firewall port.
- Generate IP Table rules.
for more information, see connecting to jumpstation.