Set up an Active—Hot-standby Cluster
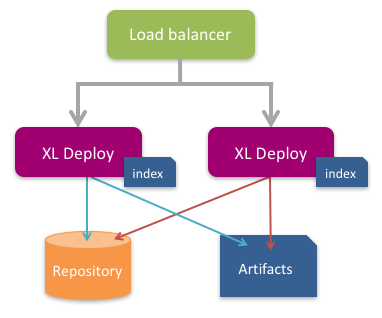
This topic covers the high availability (HA) configuration in Deploy. To support high availability (HA), you can configure Deploy in clustered active/hot-standby mode. In this mode, only one Deploy node is active at one time, while the hot standby node is ready to become active if needed.
Note: The active/hot-standby mode is not the recommended mode for HA. We recommend active-active HA setup. For more information about active-active setup, see Set up an active-active cluster.
Requirements
Using Deploy in active/hot-standby mode requires the following:
-
System requirements: Meet the standard system requirements for Deploy.
Important: Active/hot-standby is not supported on Microsoft Windows.
-
External repository: Store the Deploy repository in an external database using the instructions in this topic. If you are using the default Deploy configuration, which stores the repository in an embedded database, you need to migrate all of your data to an external database before you can start to use active/hot-standby.
-
Load balancer: Use a load balancer that supports hot-standby and health checking using HTTP status codes. This topic provides an example of how to set up a HAProxy load balancer.
-
Artifact storage: Binary data (artifacts) can be stored in the external Deploy database or in a filesystem such as NFS. If you store artifacts in a filesystem, it must be shared so that both the active and standby Deploy nodes can reach it. Note: To store artifacts in the Deploy database, use the setting
xl.repository.artifacts.type = dbindeploy-repository.yaml, as described in this document. -
Time settings: The time on both Deploy nodes must be synchronized through an NTP server.
-
Firewall: The firewall must allow traffic on port 2552 in the default setup. For more information, see optional cluster settings.
Important: All the Deploy cluster nodes must reside in the same network segment. This is required for the clustering protocol to function correctly. For optimal performance, it is also recommended that you put the database server in the same network segment to minimize network latency.
Limitation on HTTP session sharing and resiliency
In active/hot-standby mode, only one Deploy node is active at any given time. The nodes use a health REST endpoint (/deployit/ha/health) to tell the load balancer which node is currently the active one. The load balancer should always route users to the active node; calling a standby node directly will result in incorrect behavior.
Deploy does not share HTTP sessions among nodes. If the active Deploy node becomes unavailable:
- All users will be logged out and will lose any work that was not stored in the database.
- Any deployment or control tasks that were running on the previously active node must be manually recovered. Tasks that were previously running will not automatically be visible from the newly active node because this may lead to data corruption in "split-brain" scenarios.
Active/Hot-standby setup procedure
The initial active/hot-standby setup consists of:
- A load balancer
- A database server
- Two Deploy servers
To set up an active/hot-standby cluster, manually configure each Deploy instance before starting:
- Provide the correct database driver
- Modify the
deploy-cluster.yamlconfiguration file
Step 1 Configure external databases
Set up an external database to be used as a repository in Deploy. The following external databases are recommended:
- MySQL
- PostgreSQL
- Oracle 11g or 12c
Where applicable, the following set of SQL privileges are required:
- REFERENCES
- INDEX
- CREATE
- DROP
- SELECT, INSERT, UPDATE, DELETE
Provide JDBC drivers
Place the JAR file containing the JDBC driver of the selected database in the XL_DEPLOY_SERVER_HOME/lib directory. Download the JDBC database drivers:
| Database | JDBC drivers | Notes |
|---|---|---|
| MySQL | Connector\J 5.1.30 driver download | None. |
| Oracle | JDBC driver downloads | For Oracle 12c, use the 12.1.0.1 driver (ojdbc7.jar). It is recommended that you only use the thin drivers. For more information, see the Oracle JDBC driver FAQ. |
| PostgreSQL | PostgreSQL JDBC driver | None. |
Step 2 Configure the repository database in Deploy
When active/hot-standby is enabled, the external repository database must be shared among all nodes. Ensure that each node has access to the shared repository database and is set up to connect to it using the same credentials.
If you are storing artifacts in a separate filesystem location, ensure that it is shared among the Deploy nodes; for example, by using NFS or by mounting the same volume.
Important: The database must be created with the correct permissions before starting Deploy. For example, the user must have CRUD access. The repository configuration in Deploy requires changes in deploy-repository.yaml, as described here.
For example:
xl.repository:
artifacts:
type: db
# alternatively (make sure to share this file location across nodes e.g. via NFS):
# type = "file"
# root = "repository/artifacts"
database:
db-driver-classname: org.postgresql.Driver
db-url: jdbc:postgresql://localhost:5432/xldrepo
db-password: password
Step 3 Set up the cluster
Provide additional active/hot-standby configuration settings in the deploy-cluster.yaml file. This file uses the .yaml format Yet Another Markup Language (YAML) format.
For each node in this file:
- Enable clustering by setting
cluster.modetohot-standby. - Provide database access to register active nodes to a membership table by adding a
cluster.membershipconfiguration containing the following keys:
| Parameter | Description |
|---|---|
jdbc.url | JDBC URL that describes the database connection details; for example, "jdbc:oracle:thin:@oracle.hostname.com:1521:SID". |
jdbc.username | User name to use when logging into the database. |
jdbc.password | Password to use when logging into the database. After you complete the setup, the password will be encrypted and stored in a secured format. |
jdbc.leak-connection-threshold | This property controls the amount of time that a connection can be out of the pool before a message is logged indicating a possible connection leak. A value of 0 means leak detection is disabled. The lowest acceptable value for enabling leak detection is 2 seconds. Increase the leak-connection-threshold to 2 or 3 minutes if the connection fails due to JDBC connection leaks. |
You can set up Deploy to reuse the same database URL, username, and password for both the cluster membership information and for the repository configuration as set in the deploy-repository.yaml file.
Here's an example deploy-cluster.yaml file:
deploy.cluster:
mode: hot-standby
membership:
jdbc:
connection-timeout: 30 seconds
idle-timeout: 10 minutes
leak-connection-threshold: 2 minutes
max-life-time: 30 minutes
max-pool-size: 1
minimum-idle: 1
password: '{cipher}dxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
pool-name: ClusterPool
url: "jdbc:mysql://db/xldrepo?useSSL=false"
username: <my_username>
For additional configuration you can perform in the deploy-cluster.yaml file, see Optional cluster settings.
Step 4 Set up the first node
- Open a command prompt and point to
XL_DEPLOY_SERVER_HOME. - Execute
./bin/run.sh -setupfor Linux-based systems, orrun.cmd -setupfor Microsoft Windows. - Follow the on-screen instructions.
Step 5 Prepare each node in the cluster
- Compress the distribution that you created in Step 3 Set up the cluster into a ZIP file.
- Copy the ZIP file to all other nodes and unzip each one.
Note: You do not need to run the server setup command on each node.
Step 6 Set up the load balancer
To use active/hot-standby, use a load balancer in front of the Deploy servers to direct traffic to the appropriate node in the configuration. The load balancer must check the /deployit/ha/health endpoint with a GET or a HEAD request to verify that the node is up.
This endpoint will return:
- A
503HTTP status code if this node is running as standby (non-active or passive) node. - A
404HTTP status code if the node is down. - A
204HTTP status code if this is the active node. All user traffic should be sent to this node.
Note: Performing a simple TCP check or GET operation on / is not sufficient. This check will only determine if the node is running and will not indicate if it is in standby mode.
For example, using HAProxy, you can add the following configuration:
backend default_service
option httpchk get /deployit/ha/health HTTP/1.0
server xl-deploy1 <XL_DEPLOY_1-ADDRESS>:4516 check inter 2000 rise 2 fall 3
server xl-deploy2 <XL_DEPLOY_2-ADDRESS>:4516 check inter 2000 rise 2 fall 3
Step 7 Start the nodes
Starting with the first node that you configured, start Deploy on each node. Ensure that each node is fully up and running before starting the next one.
Handling unreachability and network partitions ("split-brain" scenarios)
Transient network failures can affect Deploy nodes that are in hot-standby mode. These nodes will continually check the reachability of other nodes by sending messages and expecting responses.
The cluster will detect the affected nodes as being unreachable due to various reasons, including when:
- A network experiences a temporary outage or congestion (example: a network partition)
- A Deploy node crashes or is overloaded and cannot respond in time
It is not possible to distinguish between these occurrences from inside the cluster. You can employ one of the strategies described below deal with unreachable members.
Note: None of these strategies apply for graceful shutdown of Deploy nodes. During a graceful shutdown, the cluster will be properly notified by the leaving member and immediate handover will take place.
Strategy: Keep the oldest member
When nodes cannot detect the original active node for a period of time, they will shut down to prevent two nodes being active at the same time. This strategy prevents data loss. If a long-lasting network partition occurs, or if the active node crashes unexpectedly, it can result in the shutting down of most or all cluster nodes.
Note: The graceful shutdown of Deploy nodes will continue to be handled using managed handover and a single new active node will be selected automatically.
To use this strategy, add the following settings in the cluster section of deploy-cluster.yaml:
pekko:
cluster:
downing-provider-class: "com.xebialabs.xlplatform.cluster.full.downing.OldestLeaderAutoDowningProvider"
custom-downing:
stable-after: "10s"
down-removal-margin: "10s"
See Optional cluster settings for more information.
Strategy: Keep the majority
When network partition occurs, the partition with the majority of nodes will stay active and the nodes in the minority partition will shut down. This strategy requires an odd number of total nodes (at least 3) and guarantees that the majority of nodes stay active. If the currently active node is on the minority partition, an unnecessary handover can take place.
To use this strategy, add the following settings in the cluster section of deploy-cluster.yaml:
pekko:
cluster:
downing-provider-class:"com.xebialabs.xlplatform.cluster.full.downing.OldestLeaderAutoDowningProvider"
custom-downing:
stable-after: "10s"
down-removal-margin: "10s"
See Optional cluster settings for more information.
Strategy: Manual
If none of the above strategies apply to your scenario, you can use the manual strategy. To use this strategy, add this setting in the cluster section of deploy-cluster.yaml:
pekko:
cluster:
auto-down-unreachable-after: "off"
In this strategy, an operator must perform manual monitoring and intervention which can be achieved using JMX MBeans.
- The MBean
pekko.Clusterhas an attribute namedUnreachablethat lists the cluster members that cannot be reached from the current node. Members are identified by IP address and pekko communication port number (2552by default , see Optional cluster settings below). - If there are unreachable members, a log line will also appear in the Deploy logs periodically while the situation persists.
Note In this strategy, reachability of members will have no influence on any nodes being, becoming, or going active, in stand-by, or down. If the active node goes down (for example, a crash and not a network partition), no other node will become active automatically. This results in longer downtime of the overall active/hot-standby Deploy system.
If a cluster member is reported as unreachable on any (other) node, an operator must verify if that member is actually down or whether this is only caused by a network partition.
If the node is down, the operator must remove it by de-registering it from the cluster manually. The same pekko.Cluster MBean as above has a down(...) operation that requires the IP address and communication port number (as from the Unreachable attribute). This must be done only on a single node of the remaining cluster. The information will spread throughout the cluster automatically. Once all unreachable members have been removed from the cluster, automatic election of a new active member will take place if necessary.
See Optional cluster settings for more information.
Sample deploy-task.yaml and deploy-cluster.yaml configuration
This section provides a sample of the configuration for one node that uses a MySQL repository database to store its cluster membership information.
Note: The Deploy repository is configured in deploy-task.yaml, but it can reuse the same database settings.
deploy-task.yaml
| Property | Description | Default value |
|---|---|---|
| deploy.task.recovery-dir | The task recovery directory location. This path can be relative (to Deploy home installation) and also absolute. | "work" |
| deploy.task.step (Subgroup) | ||
| deploy.task.step.retry-delay | Delay between each retry. | "5 seconds" |
| deploy.task.step.execution-threads | How many threads to keep for step execution. | 32 |
deploy-cluster.yaml
deploy:
cluster:
pekko:
actor:
loggers:
- org.apache.pekko.event.slf4j.Slf4jLogger
loglevel: INFO
provider: org.apache.pekko.cluster.ClusterActorRefProvider
cluster:
auto-down-unreachable-after: 15s
custom-downing:
down-removal-margin: 10s
stable-after: 10s
downing-provider-class: ''
membership:
heartbeat: 10 seconds
jdbc:
connection-timeout: 30 seconds
idle-timeout: 10 minutes
leak-connection-threshold: 2 minutes
max-life-time: 30 minutes
max-pool-size: 1
minimum-idle: 1
password: '{cipher}xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
pool-name: ClusterPool
url: 'jdbc:mysql://db/xldrepo?useSSL=false'
username: 'username'
ttl: 60 seconds
mode: hot-standby
name: xld-hotstandby-cluster
Optional cluster settings
You can optionally configure the following additional settings in the cluster section of deploy-cluster.yaml:
| Parameter | Description | Default value |
|---|---|---|
name | The hot-standby management name. | xld-hotstandby-cluster |
membership.jdbc.driver | The database driver class name. For example, oracle.jdbc.OracleDriver. | Determined from the database URL |
membership.heartbeat | How often a node should write liveness information into the database. | 10 seconds |
membership.ttl | How long liveness information remains valid. | 60 seconds |
pekko.remote.netty.tcp.hostname | The hostname or IP that Deploy uses to communicate with the cluster. | Auto-determined |
pekko.remote.netty.tcp.port | The port number that Deploy uses to communicate with the cluster. | 2552 |
pekko.cluster.downing-provider-class | The strategy to use for handling network partitions. | pekko.cluster.sbr.SplitBrainResolverProvider |
pekko.cluster.custom-downing.down-removal-margin | The amount of time before the handover activates. | none |
pekko.cluster.custom-downing.stable-after | How much time must pass before the network is marked stable. | none |
Note the following:
-
Cluster bootstrapping: The
heartbeatandttlsettings are relevant for cluster bootstrapping. A newly-starting node will search in the database to find live nodes and try to join the cluster with the givennamerunning on those nodes. -
IP address registration: The
pekko.remote.netty.tcp.hostnamesetting determines which IP address the node uses to register with the cluster. Use this when the node is on multiple networks or broadcasts its presence as127.0.0.1:2552. Other nodes may not be able to see it, resulting in multiple active nodes. Check yourdeployit.logfor entries like this:2018-08-24 13:08:06.799 [xld-hotstandby-cluster-pekko.actor.default-dispatcher-17] {sourceThread=xld-hotstandby-cluster-pekko.actor.default-dispatcher-17, pekkoSource=pekko.tcp://xld-hotstandby-cluster@127.0.0.1:2552/user/$b, sourceActorSystem=xld-hotstandby-cluster, pekkoTimestamp=13:08:06.797UTC} INFO c.x.x.c.m.ClusterDiscoveryActor - Starting node registration -
Unreachability settings: The
auto-down-unreachable-aftersetting is used in the default unreachability handling strategy. This setting defines the time needed for a cluster to detect if a node is down. If the active node has been unreachable for this time, a standby node will be activated.- If you change this setting to a smaller value, the hot-standby takeover will occur within a shorter time period. For transient network issues, this can cause a takeover while the original node is still alive.
- If you use a longer value, the cluster is more resilient against transient network failures. The takeover takes more time when a crash occurs.
- If you want manual control over the activation process, change the setting to
off. For more information, see Strategy: Manual.
-
Handling network partitions: The
downing-provider-classsetting specifies which automatic strategy to use for handling network partitions. This setting is optional. The possible values are:com.xebialabs.xlplatform.cluster.full.downing.OldestLeaderAutoDowningProvider. See Strategy: Keep the oldest membercom.xebialabs.xlplatform.cluster.full.downing.MajorityLeaderAutoDowningProvider. See Strategy: Keep the majority
-
Determining when network partitioning handling strategy starts: For either strategy that uses the
downing-provider-classsetting, thestable-afteranddown-removal-marginsettings are required. These settings determine when the networking partition handling strategy starts. When a network partition arises, there is a period when nodes are fluctuating between reachable and unreachable states. After a period of time situation will stabilize.- The
stable-aftersetting determines how much time to wait for additional reachable/unreachable notifications before determining that the current situation is stable. - The
down-removal-marginsetting is an additional timeout in which proper handover will be arranged. - The recommended value for these settings for clusters of up to ten nodes is
10s.
- The
-
Password encryption: After the first run, passwords in the configuration file will be encrypted and replaced with Base64-encoded values.
Sample haproxy.cfg configuration
This is a sample haproxy.cfg configuration exposing proxy statistics on port 1936 (with credentials stats/stats). Change the bottom two lines to match your setup. Ensure that your configuration is hardened before using it in a production environment. For more information, see haproxy-dconv.
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
log-send-hostname
maxconn 4096
pidfile /var/run/haproxy.pid
user haproxy
group haproxy
daemon
stats socket /var/run/haproxy.stats level admin
ssl-default-bind-options no-sslv3
ssl-default-bind-ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES128-SHA:DHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:AES128-GCM-SHA256:AES128-SHA256:AES256-GCM-SHA384:AES256-SHA256
defaults
balance roundrobin
log global
mode http
option redispatch
option httplog
option dontlognull
option forwardfor
timeout connect 5000
timeout client 50000
timeout server 50000
listen stats
bind :1936
mode http
stats enable
timeout connect 10s
timeout client 1m
timeout server 1m
stats hide-version
stats realm Haproxy\ Statistics
stats uri /
stats auth stats:stats
frontend default_port_80
bind :80
reqadd X-Forwarded-Proto:\ http
maxconn 4096
default_backend default_service
backend default_service
option httpchk HEAD /deployit/ha/health HTTP/1.0
server xl-deploy1 <XL_DEPLOY_1-ADDRESS>:4516 check inter 2000 rise 2 fall 3
server xl-deploy2 <XL_DEPLOY_2-ADDRESS>:4516 check inter 2000 rise 2 fall 3