High Availability With Master-Worker Setup
In Deploy, deployment tasks and control tasks are executed by the task execution engine. See Deploy Tasks. Based on your deployment task, the Deploy planner generates a deployment plan or control task plan with steps that Deploy will carry out to deploy an application. You can manually modify the plan. When the plan is ready, Deploy generates a DeploymentTask or ControlTask that is sent to the task execution engine.
As of Deploy 9.0, the preferred production setup is a new high-availability implementation using an active/active setup where the (stateful) task execution engine(s) are separated from the core (stateless) Deploy server(s) called the master instance(s). The tasks in Deploy are then executed by one or more external execution engine processes called workers. Using this master-worker setup you can dynamically scale up your deployment capacity. The older active/hot-standby implementation is still available, see Configure Active/Hot-standby mode.
Preparing multiple masters
For high availability, you must configure multiple master instances. Although these master instances do not need to know about each other, workers must be connected to each of them, as described in the section below. You must front the Deploy masters with a load balancer that supports sticky sessions based on session cookies, so that user traffic from the same user ends up on the same Deploy master.
For the export of reports and CI trees to work seamlessly across multiple masters, the XL_DEPLOY_SERVER_HOME/export folder must be on a shared file system that each of the masters and workers has read-write access to. The user that the Deploy master or worker runs as must have permissions to create and destroy files and folders on that file system.
Supported worker setups
You can set up workers in various ways:
- In-process worker: The default out-of-the-box configuration contains a worker that is part of the master and runs in the same process. This is called an in-process worker and it is unique.
This option is not recommended in a high availability setup.
- Local workers: These workers run in separate processes but are located on the same machine and run in the same installation directory as the Deploy master.
- External workers: These workers also run in separate processes. They can either be located on different machines from the master, or on the same machine as the master, but in a different installation directory.
The Master-Worker setup enables you to scale Deploy by adding multiple workers connected to a master to execute more tasks from Digital.ai Deploy. In Deploy 9.0.x, the task is created on the master instance and sent to a worker to be executed. A worker can have multiple tasks assigned to the execution queue. Whereas from 9.5.0 onwards, tasks are sent to a shared JMS queue, where they get picked up by any of the workers (for more information, see Configure task queueing). In any version, each task can be assigned to only one worker.
When you install Deploy, the default configuration is to execute the tasks by an in process worker that runs in the same process as the master.
You can change the default configuration and use multiple workers that run in different processes from the master. You cannot use the in-process worker and other workers in the same configuration.
Default configuration with in-process worker
When you install a Deploy instance, the default configuration is to execute the tasks on an internal worker that runs in the same process as the master. This setting is defined in the deploy.task.in-process-worker=true property in the deploy-task.yaml file.
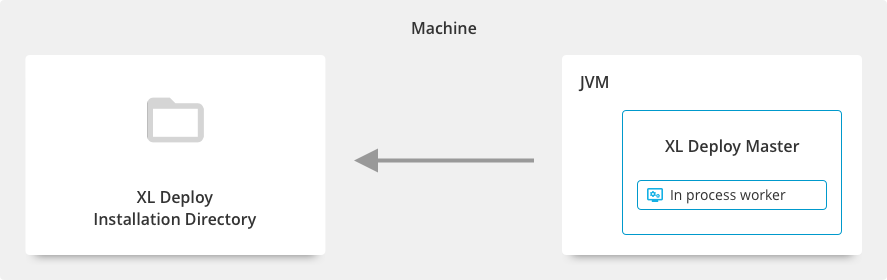
This configuration is not intended for production environments.
Configure Deploy to use multiple workers
The worker is a task executor that is running in a different Java process from the Deploy master process. To start a worker, it must have an identical classpath with the master. Specifically, the folder structure, contents, and plugins must be identical and it must use the same database. Workers will not be available for execution of new tasks from the Master if their plugins differ. See also Changing configuration of masters and workers.
Custom configurations with workers
Master and workers in one folder location (Deprecated)
Note: From Deploy 22.0, this configuration is no longer supported.
You can start a separate Java process for each worker from the same folder location as the master. These are called local workers.
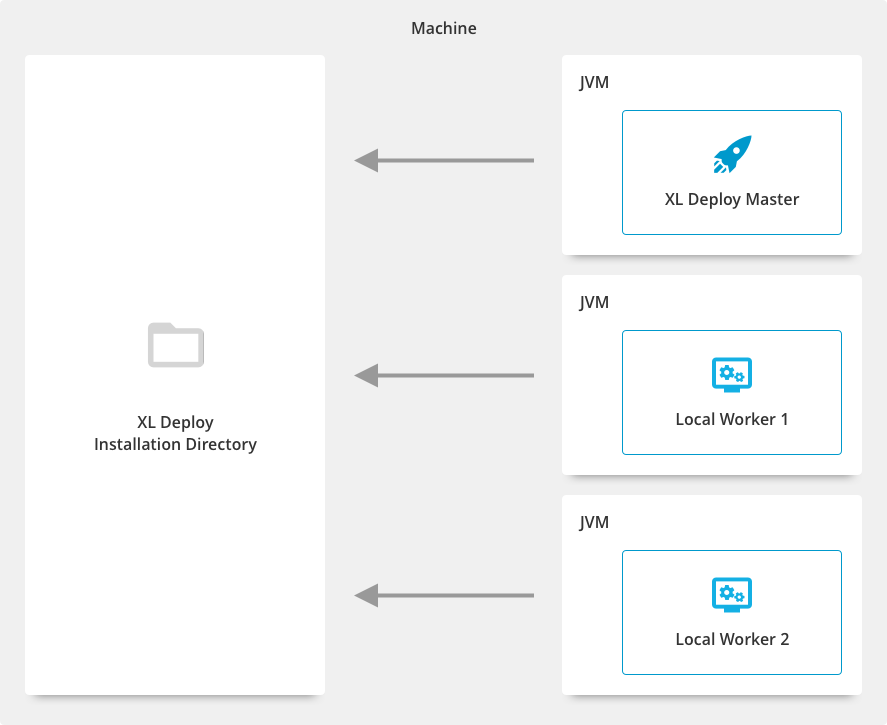
This setup provides improved availability and a faster Deploy restart procedure for simple configuration changes such as a new plugin or configuration files updates. You can use the startlocalworker script to quickly add new workers. Ensure that you allocate for each worker the same resources required for the master.
Master and workers in separate folder location on the same machine
- Download the Deploy-Task-Engine from the Deploy Software Distribution site (requires customer log in).
- Start the process from the new location.
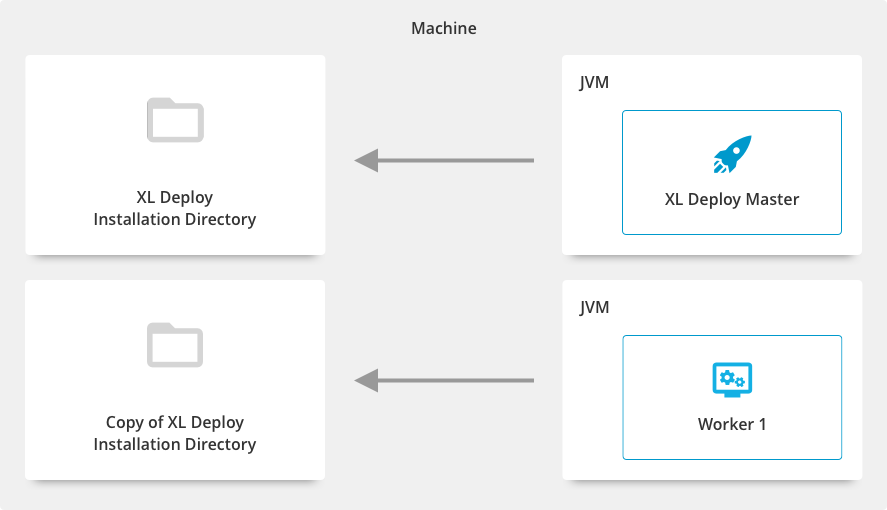
This setup supports a faster restart procedure of Deploy for advanced configuration changes such as replacing or removing a plugin. Ensure that for each worker you allocate the same resources as required for the master.
Master on one machine and workers on separate locations on different machines
- Download the Deploy-Task-Engine from the Software Distribution site to a location on the different machine for each worker.
- Start the process from the new location. Note: The master and the registered workers must all exist in the same subnetwork.
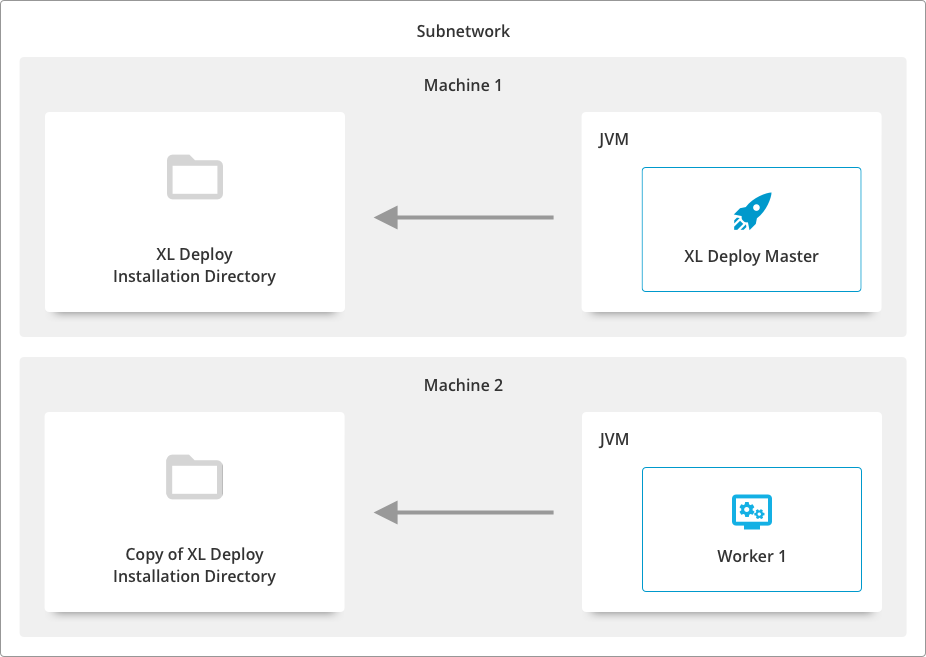
This setup supports high availability and better scalability for Deploy by using multiple machines to run workers connected to one or more masters.
System Requirements
If you are running Deploy with an in-process worker configuration, see Requirements for installing Deploy.
If you are running Deploy with multiple workers on the same machine, ensure that you allocate the same resources for each worker as for the master. A worker process has the same resource requirements as the master process.
Network connectivity
If you are running Deploy in a configuration with multiple workers on different machines, the master and the workers must reside in the same sub-network.
Security
To configure secure communication between master and workers, refer to Configure secure communication with workers and satellites.
Changing configuration of masters and workers
The master-worker setup allows for high availability of Deploy. Deploy needs to be restarted for configuration, plugin, type system changes, or upgrades. With the master-worker setup, you can safely restart Deploy masters without waiting for all the running tasks to be completed. The tasks are executed by the workers and will continue to run on the existing configuration while the master is restarted.
After Deploy is restarted with the new configuration, you must manually synchronize the configuration for the existing workers. The master will not assign new tasks to workers that have the old configuration. You can either register new workers to the master, or free up workers before restarting the Deploy master.
Upgrades to Deploy that include database changes or breaking type system changes still require a complete Deploy restart and cannot be performed while parts of the system are running.
Deployments with the master-worker setup
When you perform a deployment, the deployment mapping and the planning are created on the master instance. The control task or deployment task is sent to a worker which then executes the steps of the plan. In Deploy 9.0.x, each task from the master is assigned directly to a single worker. The Deploy master uses a round-robin task scheduling method to assign tasks to workers. The method consist of assigning tasks one by one, to each worker in the list having the same configuration and plugins as the master itself. As of Deploy 9.5.0, tasks are put onto a shared JMS 2.0 queue, and workers pick up tasks from that queue as they have capacity. For more information, see Configure task queueing.
Crashes, shutdowns, and task recovery on workers
Whenever a task is executed on a worker, a task recovery file will periodically be written to the work directory, to keep track of what the task looks like and which parts of the task have already been executed. In case of a worker crash, or when the worker is terminated, the worker can be restarted; it will find these .task files and recover the deployment tasks as usual. See also The Deploy work directory and Understanding tasks in Deploy).
For a successful recovery to happen, the work directory and the location where the .task files are kept must be persistent across worker restarts.
When a task is not properly archived, i.e. it has (partially) executed but is not yet finished or canceled; and the worker that it was running on is unavailable (e.g. due to a crash, termination, or network issues), the task monitor will show the task as being in an UNKNOWN state. Once the worker becomes available again (network issues resolved, or worker restarted and task recovered), the task will again be shown in its proper state. If a task is not recoverable, it can be removed from the Task Monitor screen. If a task is removed in this way, and the worker becomes available anyway, the task will be a ghost task on the worker since Deploy no longer knows about it. You can tell all workers to re-register any ghost tasks at once by using the CLI. Point the CLI to one of the masters, and issue the workers.restoreGhostTasks() command. See also Task states.
Once a worker detects it has a configuration mismatch with one of the masters, or when it is told explicitly to shut down (using the Workers monitoring screen from the GUI), it will announce to all masters that it is going into draining mode. Masters will no longer send new tasks to this worker, and when the last tasks executing on this worker have finished (canceled or archived) it will gracefully shut down. Once it is shut down, it can be decommissioned, or its plugins and configuration brought up-to-date with the masters'. See also Draining workers
Comparing workers and satellites
These are the main characteristics that differentiate workers and Deploy Satellites:
| Worker | Satellite | |
|---|---|---|
| Network topology | Workers should reside on the same machine or in the same network as the master for stability, speed, and reduced latency. | Satellites can exist in a data center away from the master or workers. |
| Network stability | Workers and master must reside in the same stable network. | Satellites can be connected by unstable networks. |
| Task execution | One task is assigned to one worker. | Satellites execute a part of a task containing block of steps. One deployment task can involve multiple satellites. The host that you deploy to determines which satellites execute the block. |
| Functionality | Full functionality and identical to the master. | Limited functionality, does not require access to all resources. Satellites are CIs that exist in the Deploy repository and cannot execute all step types. |
Satellites can be used with all master-worker configurations.
For more information about Deploy Satellites, refer to Getting started with the satellite module.
Communication between master and worker
Communication between the master process and the worker process when sending data is done through two channels.
From master to worker
- When you start a new worker, you must specify the DNS address of the master. The worker registers with the master.
- (In 9.0.x) The master selects a worker and sends a task to execute it.
- The master sends instructions to the worker such as starting the task, pausing the task, etc.
All of the command information is pushed from the master to the worker. These tasks are communicated through one command channel.
Resolution of the master hostname is by default done by DNS lookup, which should return an SRV record listing all the masters, or an A record if there is just a single master. The DNS server is polled every few seconds, and the worker will dynamically connect to new masters or disconnect from removed masters whenever changes in the SRV record listing occur.
From worker to master
The second channel of communication is in the other direction, from the worker to the master, through the REST API. This is used when a worker must perform an action that is only available on the master.
To set up the communication, you must specify the locations for these channels when you start a worker. For more information, see Add, start, and use workers
Overview of workers in Deploy
In the Explorer, workers are shown in the Monitoring section under Workers. The list contains the following information:
| Name | Description |
|---|---|
| ID | A unique (technical) identifier of the worker. |
| Name | The user assigned name of the worker (not unique). |
| Address | The (technical) unique address of the worker containing hostname and port. |
| State | The state that the worker is in. |
| # Deployment tasks | The number of deployment tasks assigned to the worker. |
| # Control tasks | The number of control tasks assigned to the worker. |
The state of a worker can be:
| Name | Description |
|---|---|
| Connected | The worker is connected to the master and can be used to execute tasks. |
| Incompatible | The worker is connected to the master, but is on a different configuration. The master will not send new tasks to this worker. This is a temporary state, while the system is being updated. |
| Draining | The worker is shutting down once all tasks are completed (cancelled or archived). The master will not send new tasks to this worker. |
| Disconnected | The worker is not connected to the master. This can occur due to network interruptions, a failure of the machine, or an issue in the worker. The master displays the number of deployment or control tasks that are running on it, but these tasks cannot be managed. |
The Incompatible state can be seen only on systems with multiple masters. You see this state when the master that the user is connected to has a different configuration than the worker, but the worker is not in a draining mode since it is still compatible to one of the other masters. To get rid of the Incompatible state, you must make sure that all masters have the same configuration, and the workers have been made to go to draining mode.
You can enhance the communication performance between your master and external worker by configuring the Configure chunking timeout.
Master-worker setup in active/hot-standby and active/active modes
When you are using Deploy in an active/hot-standby or active/active setup, the database is shared by all the Deploy master nodes. The workers you register with a Deploy master will also connect to the same database. The communication from the workers to the active Deploy master node is done through the load balancer.
The out-of-the-box evaluation setup is to have an in-process worker in each of the hot-standby master nodes. To disable the in-process worker and add other workers, set deploy.task.in-process-worker=false in the XL_DEPLOY_SERVER_HOME/centralConfiguration/deploy-task.yaml file for each master node. If you do so, then at the end of a master's startup sequence, it will output a log line saying: External workers can connect to <IP-ADDRESS>:<PORT>
There are different types of setups possible viz.
- single master (with one master and no load balancer)
- static multi-master masters (multi-master with fixed IP addresses)
- dynamic multi-masters (with dynamic scaling using DNS Service (SRV) records)
To create a worker in a hot-standby scenario:
- For the
-apiflag, specify the REST endpoint of the load balancer - Point one
-masterflag to each of the hot-standby master nodes' IP addresses and ports. (There can be multiple-masterflags)
- The
-masterswitches on the workers should not be pointed to the load balancer. However, the masters themselves must be registered with the load balancer. - In a 'static' master’s setup, you can have the multiple
-masterswitches, point to each of the masters directly. Whereas in a 'dynamic' master setup, once you set up the DNS correctly, pointing them to master using a single-masterswitch is enough. - Every worker also needs a
-apiswitch as it needs to access the API services that are only available on the masters. In a multi-master setup, the-apiswitch should always be pointed to the load balancer. However, the only exception is in the case of a single master set up with no load balancer, in which case the-apiswitch should be pointed to the master.
For examples on how to configure multiple master switches, see running workers as a service.
To create a worker in an active/active scenario:
- For the
-apiflag, specify the REST endpoint of the load balancer - Point one
-masterflag to the DNS Deploy service. The DNS service is required to return anSRVrecord containing IP addresses of each of the available Deploy master instances, or anArecord if there is only a single one.
The contents of the installation directories must be identical between all the master nodes and all the workers. Ensure all the conf, plugins, and ext folders are synchronized in all locations. See also Changing configuration of masters and workers.
To ensure high availability, add workers across multiple locations in the same subnetwork. All the workers can communicate with any active master node.
If the communication between a master and a worker fails and the worker cannot be reached, the system will display the worker in a disconnected state, and its tasks in an Unknown state. Once network connectivity is restored, the masters and workers should automatically reconnect.
Related topics
- For more information about adding, starting, and using workers, see Add, start, and use workers.
- Requirements for installing Deploy