Digital.ai Release – Multi-Datacenter High Availability (HA) Setup
![]()
The Digital.ai Release Multi-DC High Availability (HA) setup is available only with the Release Premium edition.
The Digital.ai Release Multi-DC High Availability (HA) module provides continuous uptime for Digital.ai Release when a data center suffers from an anomaly like an outage or poor network performance. This guide walks you through the capabilities and architecture of the Multi-DC HA solution. For a tailored implementation, our expert Professional Services team is ready to help you realize this architecture in your environment.
Why Multi-DC HA with Digital.ai Release?
- Uninterrupted Business Operations: Seamless failover and rapid recovery ensure your critical release pipelines and applications remain available—even in the face of datacenter outages or disasters.
- Hands-off monitoring: The Cluster Manager orchestrates health monitoring, failover, and recovery with minimal manual intervention, reducing operational risk and complexity.
- Flexible Architecture: Designed to adapt to your infrastructure.
- Observability & Control: Real-time dashboards, logs, and integration with Prometheus/Grafana.
Failover Scenarios
The Digital.ai Release Multi-DC HA solution is designed to handle the following scenarios, switching datacenter availability to ensure uptime.
- Node crashes
- Database (DB) or Load Balancer failures
- Network partitions
- Cluster Manager quorum loss
- Stress and repeat failover events
- Recovery Time Objective (RTO) and Recovery Point Objective (RPO) measurements
- RTO (Recovery Time Objective): The maximum acceptable time to restore service after a disruption
- RPO (Recovery Point Objective): The maximum acceptable amount of data loss measured in time
Key Capabilities
- Active/Passive Setup: If one data center goes down, another takes over.
- Comprehensive Monitoring: Real-time UI for status, logs, and failover history of Release clusters, database, and load balancers.
- Automated and Manual Failover: With configurable thresholds.
- Managed Transitions: Graceful shutdowns retain sessions and jobs.
- Prometheus/Grafana Compatibility: Via health and metrics endpoints.
- Enterprise Security: Role-based access, audit trails, and compliance-ready architecture
Architecture Overview
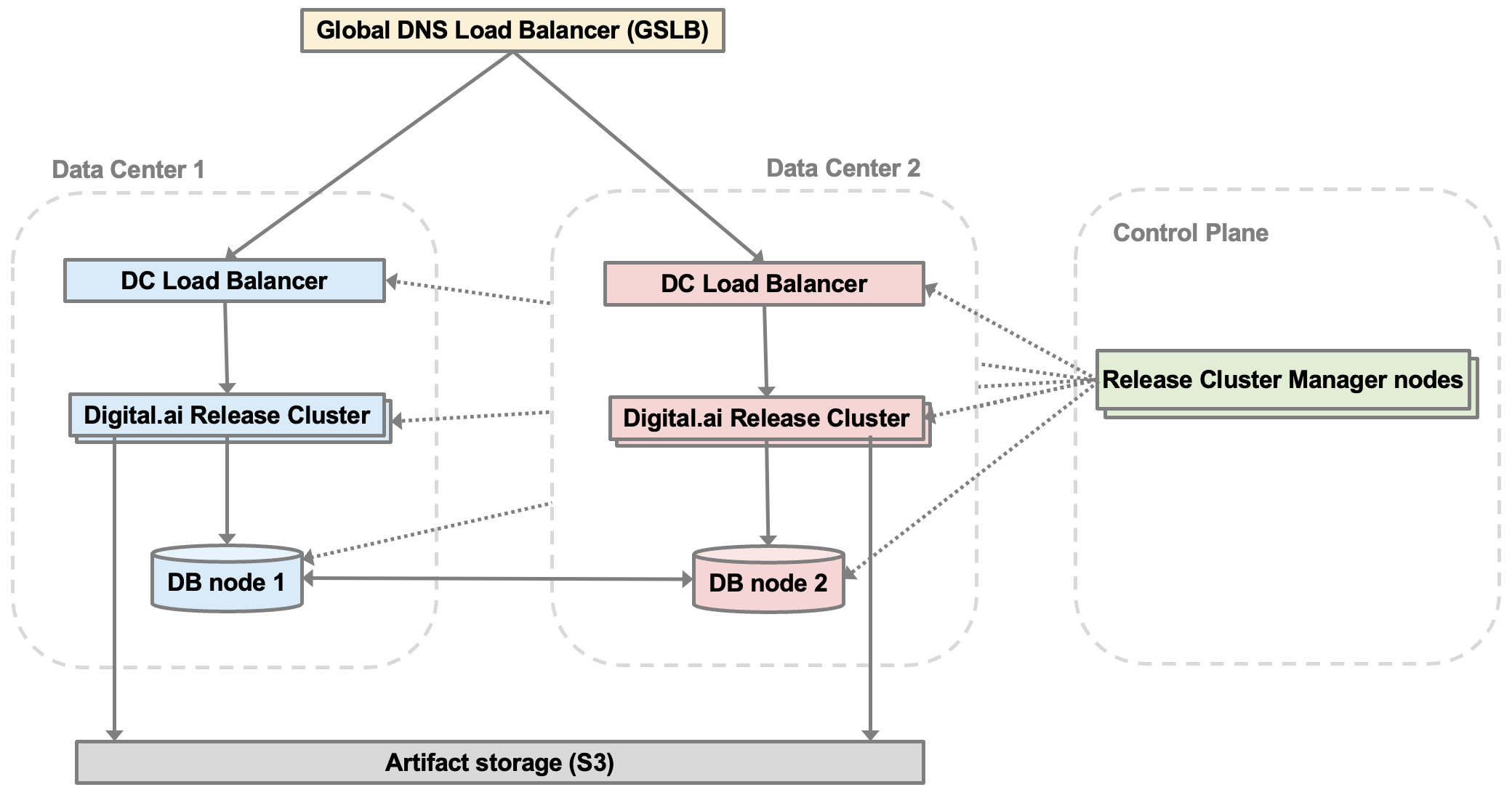
- Deployment Model: Active-Passive between two geographically separated datacenters (DCs). For example: US and EU.
- Digital.ai Release Clusters: Each datacenter hosts a cluster of at least 3 Release nodes.
- Load Balancers:
- Global: GSLB (for example, DNS-based routing) redirects users to active DC
- Local: F5/NGINX within each datacenter
- Database Topologies:
- Multi-DC High Availability (HA) is supported only with one of the following database configurations.
- EnterpriseDB Postgres Distributed (PGD) in multi-master mode
- PostgreSQL configured in active/passive (master-slave) mode
important
Other database setups are not supported for Multi-DC HA.
- Multi-DC High Availability (HA) is supported only with one of the following database configurations.
- Orchestration: Cluster Manager automates and coordinates failover
Cluster Manager Highlights
The Digital.ai Release Cluster Manager is the standalone orchestration and monitoring component that ensures high availability, automated failover, and operational transparency across multi-datacenter Release deployments. Note that the Cluster Manager does not run in the datacenters it monitors to ensure availability when disaster strikes. The Cluster Manager itself runs in a clustered setup to ensure high availability.
Key features and capabilities include:
- Comprehensive Monitoring: Continuously monitors the health of Release clusters, databases, load balancers, and synthetic monitoring endpoints (for example, Dynatrace).
- Automated Failover: Automatic failover triggered by configurable health thresholds that includes logic for cool-down intervals and quorum-based decision-making to prevent split-brain scenarios.
- Manual Failover: Supports manual failover for planned maintenance or controlled recovery.
- Quorum and Distributed Locking: Utilizes distributed locking and quorum mechanisms to coordinate failover actions and ensure only one datacenter is active at a time, maintaining data consistency and service integrity.
- Real-Time UI and Observability: Provides a web-based dashboard for real-time cluster status, logs, failover history, and actionable alerts. Integrates with enterprise observability tools (for example, Prometheus, Grafana) for unified monitoring.
- Role-Based Access Control (RBAC): Enforces enterprise security with role-based access control (RBAC), integrated with customer's Identity Provider.
- Audit Trails: Detailed audit logs where all actions and configuration changes are logged for traceability.
- Extensible Configuration: Centralized configuration allows fine-tuning of health thresholds, failover logic, notification channels, and integration points.
- Operational Best Practices: Includes support for dry-run failover testing, RTO/RPO validation, and alerting to ensure readiness and minimize downtime during real incidents.
- Resilience and Recovery: Designed to handle a wide range of failure scenarios, including node, database, network, and quorum loss.
Professional Services Engagement
This document illustrates the possibilities with Digital.ai Release Multi-DC HA. A successful implementation requires careful planning, integration, and validation. The Professional Services team brings the expertise to ensure your deployment is robust, secure, and tailored to your environment and requirements. Contact the team to learn how to realize the full value of Multi-DC HA.